I will show you how to create a Databricks and Blob storage resource on the Azure portal. Then we will create a cluster on Databricks and write a script to connect Azure Databricks to Azure blob storage in part 2 of this blog.
Let’s get started.
Create an Azure Databricks Service
You will need an Azure subscription to begin with. If you do not have one create one for free by going here.
Sign in to Azure portal and click on Create a resource and type Databricks
Click on create
You will see the following screen
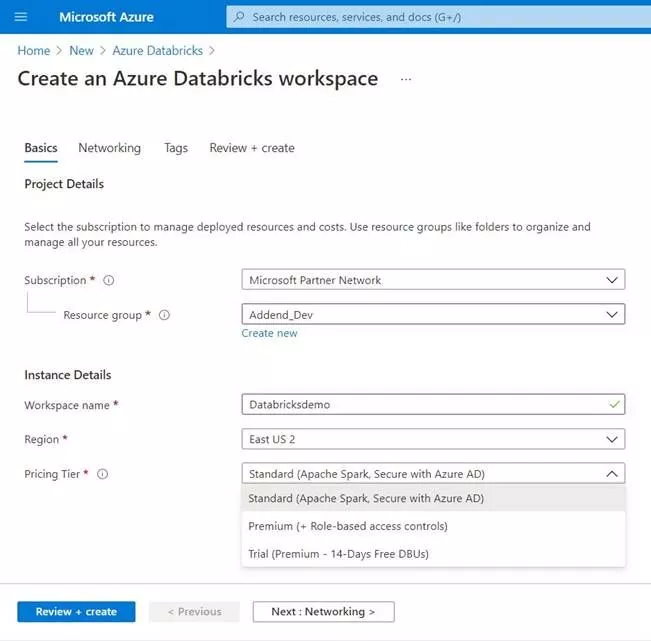
- Subscription: Select your subscription
- Resource Group: Create a new resource group or use an existing one if you already have it created.
- Workspace name: Enter a workspace name of your liking
- Region: Select a region closest to you
- Pricing tier: Go for the trial version if you are just getting started with Databricks.
Click on Review + create. In a couple of minutes your workspace should be created in the specified Resource group. Go to the resource and click on Launch Workspace. You will see the following screen:
Creating a cluster.
On the left-hand menu click on the Clusters option. Then you will see the below screen to create a cluster.
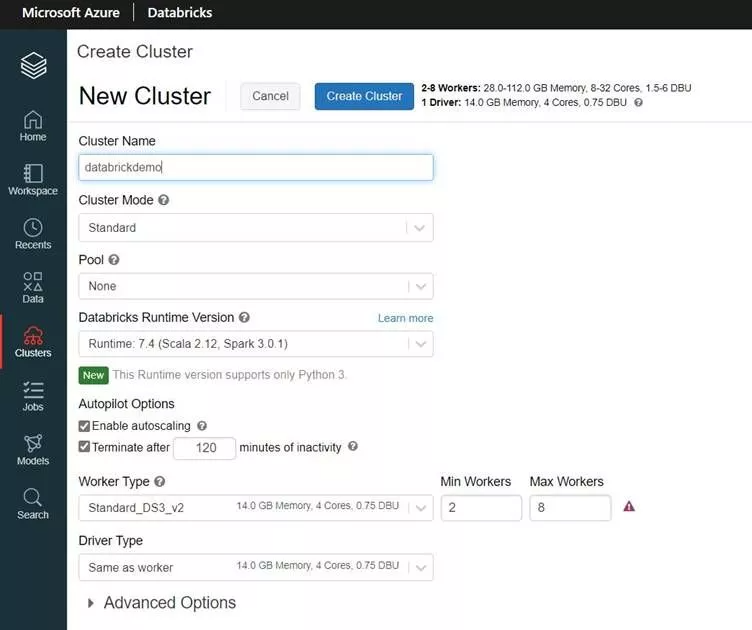
- Cluster name: Give a suitable cluster name
- Cluster mode: There are 3 options.
- Standard- (By default choose this option). Choose this option if your workload is not extensive and if you are fine with resources getting hogged by a single user when multiple people are running workloads on the same cluster.
- High concurrency- Choose this option when you know many people are going to be simultaneously working on this cluster. This mode does not support the Scala language.
- Single Node – This cluster has no workers and runs Spark jobs on the driver node. In contrast, Standard mode clusters require at least one Spark worker node in addition to the driver node to execute Spark jobs. Use this for lightweight workloads.
- Pool: To reduce cluster start time, you can attach a cluster to a predefined pool of idle instances. When attached to a pool, a cluster allocates its driver and worker nodes from the pool. We will keep it as None for this tutorial.
- Databricks Runtime version: Databricks runtimes are the set of core components that run on your clusters. There are many options available here some of them optimized for specific purposes. We will use a stable runtime instead of the latest one here.
- Autoscaling: Enable autoscaling if you are workload is unpredictable. When you create an Azure Databricks cluster, you can either provide a fixed number of workers for the cluster or provide a minimum and a maximum number of workers for the cluster. When you provide a fixed size cluster, Azure Databricks ensures that your cluster has the specified number of workers. When you provide a range for the number of workers, Databricks chooses the appropriate number of workers required to run your job. This is referred to as autoscaling. We will keep it disabled here.
- If you keep a cluster running it is going to cost you. So Azure Databricks provides you the option to automatically terminate a cluster if there has been no activity for a certain duration. Put a value between 10 mins and 60 mins depending upon your requirement.
- Select a Worker and Driver type depending upon your workload.
Then hit Create Cluster on the top. It will take some time to create and start the cluster
Create a notebook
A notebook in the spark cluster is a web-based interface that lets you run code and visualizations using different languages. Once the cluster is up and running, you can create notebooks in it and also run Spark jobs. In the Workspace tab on the left vertical menu bar, click Create and select Notebook:
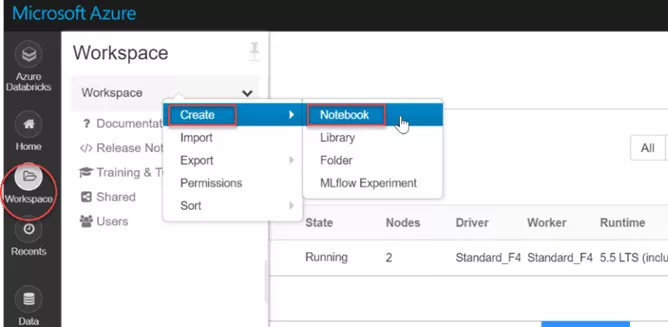
Name the notebook, choose your preferred language and select a cluster you want your notebook to be attached. Make sure the cluster is turned on
Create Blob storage and upload a csv file into the container
First, you need to create a Storage account on Azure. Go here if you are new to the Azure Storage service. Then we will upload a .csv file on this Blob Storage container that we will access from Azure Databricks.
After creating the storage account, we create a container inside it.
Create a new container by clicking on + Container as shown below
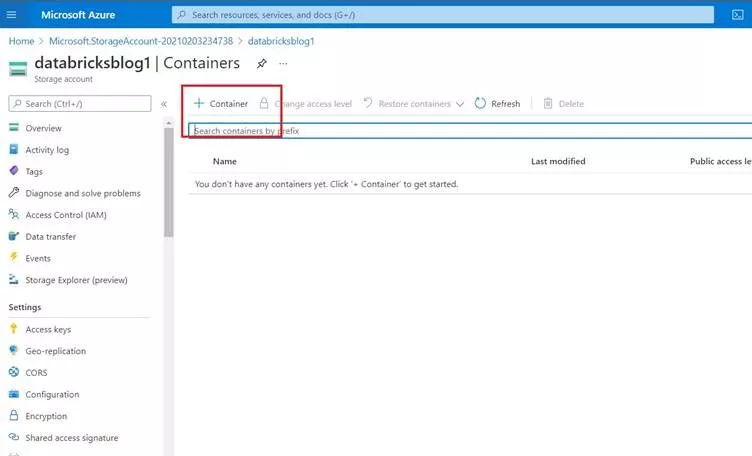
Type a name for the container, I am selecting the default access level as Private and finally hit the Create button
After creating the container open it and upload a csv file there by clicking the upload button as shown below. You can find the two csv files here. We will use these files to run a python script in the next part of the blog.
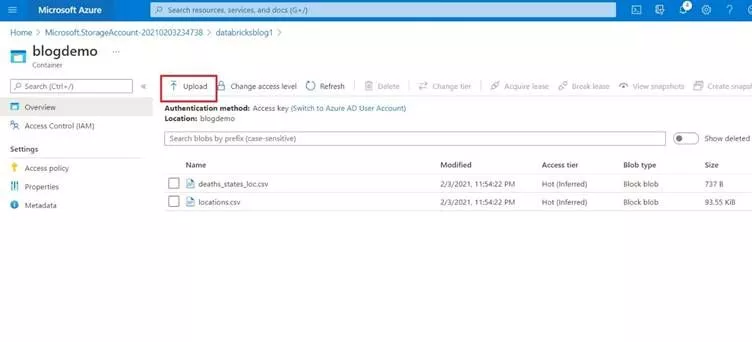
Now the Azure Storage account structure looks somewhat like this: Azure Storage Account (databricksblog1) >> Container (blogdemo) >> Block Blob (.csv files).
In the next part of the blog, we will mount blob storage to Databricks and do some transformations in the notebook.









0 Comments